

The development time with Selenium was very hight. Took me ages to figure the headless mechanism to optimize the downloads for speed. Then came along the humble POST request!
Last week one friend suggested making POST requests directly without needing to use Selenium like tools. For example you could fetch the HTML –
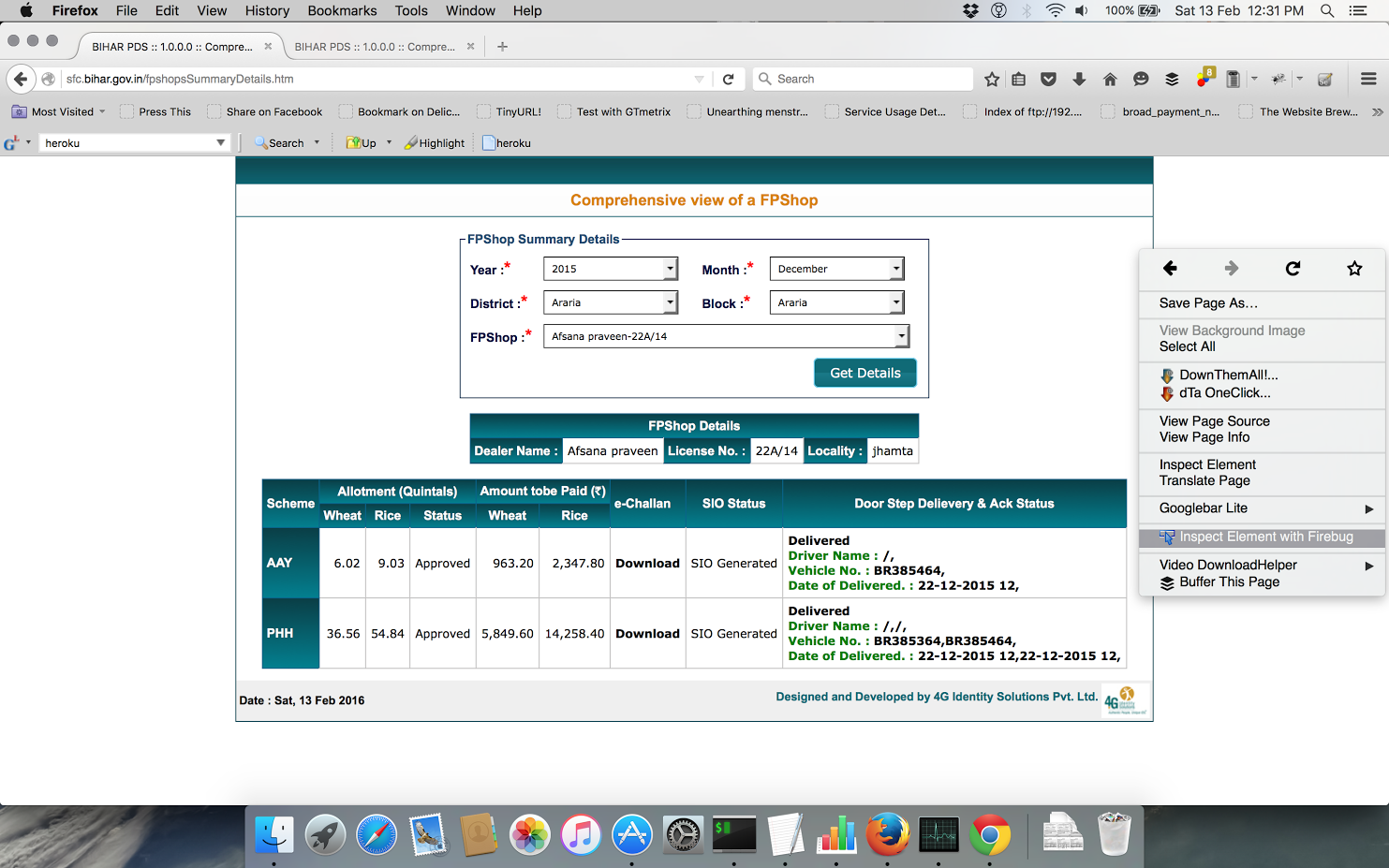
You need to fill the data as desired and check the POST request soon after you click Get Details on Firebug, Tamper Data or some such plugin. You can use the inbuilt Firefox Inspect Element on right click > Network –
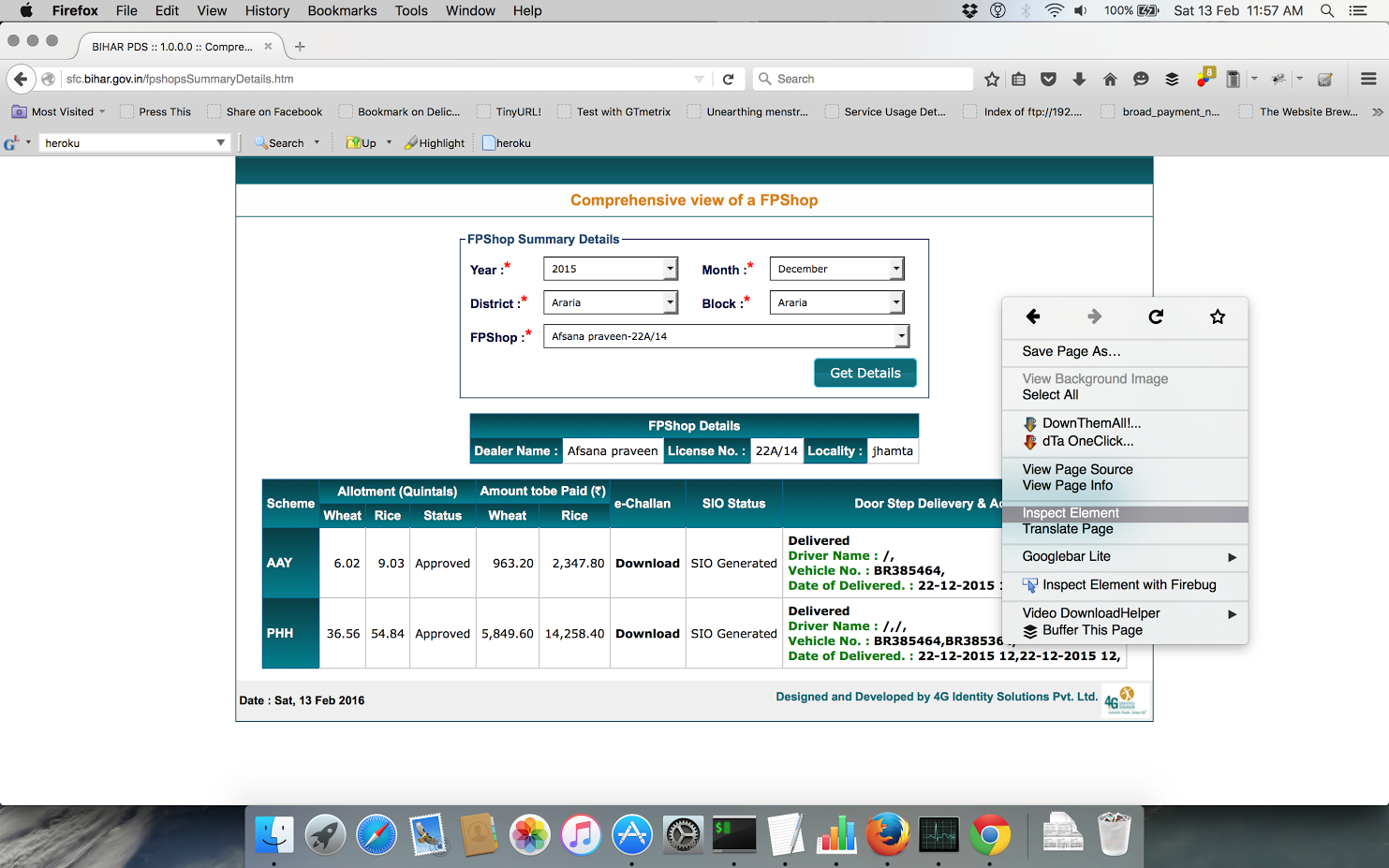
If you use Firebug –
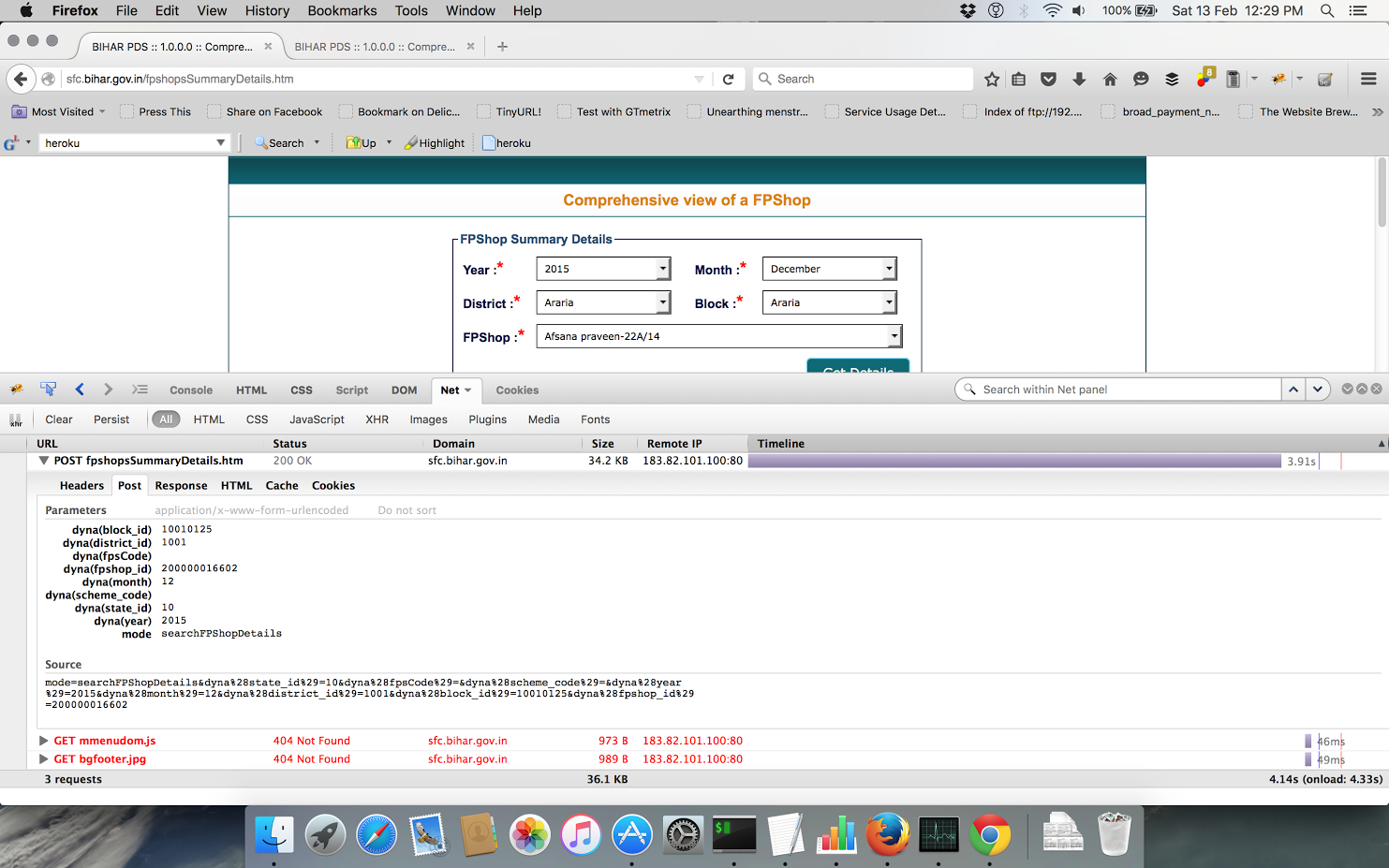
You can click on Net and check the Post Data Parameters below Source :
With Firebug/Tamper Data plugin it is easier to copy all the parameters and then used wget to get the page on Mac/Linux –
$ wget http://sfc.bihar.gov.in/fpshopsSummaryDetails.htm –referer http://sfc.bihar.gov.in/fpshopsSummaryDetails.htm –post-data‘mode=searchFPShopDetails&dyna%28state_id%29=10&dyna%28fpsCode%29=&dyna%28scheme_code%29=&dyna%28year%29=2015&dyna%28month%29=12&dyna%28district_id%29=1001&dyna%28block_id%29=10010125&dyna%28fpshop_id%29=200000016602′ -O z.html
It might be a challenge to figure the wget command. If you do a right click on source and copy as curl command you can get the same directly –
curl ‘http://sfc.bihar.gov.in/fpshopsSummaryDetails.htm’ -H ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’ -H ‘Accept-Encoding: gzip, deflate’ -H ‘Accept-Language: en-US,en;q=0.5’ -H ‘Connection: keep-alive’ -H ‘Cookie: JSESSIONID=509299ED723039BD9234D34847A0D420; SESSd7b5f50d08ae4ff60a671f33226f2b06=lspbxMpGsYn_8IlgXJXszmpDsyMQMbX_JJGAGSq-i3o’ -H ‘Host: sfc.bihar.gov.in’ -H ‘Referer: http://sfc.bihar.gov.in/fpshopsSummaryDetails.htm’ -H ‘Upgrade-Insecure-Requests: 1’ -H ‘User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:49.0) Gecko/20100101 Firefox/49.0’ -H ‘Content-Type: application/x-www-form-urlencoded’ –data ‘org.apache.struts.taglib.html.TOKEN=afa40b49a9fec29a7f6e3edf5f7996d8&mode=searchFPShopDetails&dyna%28state_id%29=10&dyna%28fpsCode%29=&dyna%28scheme_code%29=&dyna%28year%29=2016&dyna%28month%29=11&dyna%28district_id%29=1001&dyna%28block_id%29=10010125&dyna%28fpshop_id%29=200000012070&FIELD_NAME=3ae03c10-5cbe-4ac3-af8c-9b95b4b4d801&org.apache.struts.taglib.html.TOKEN=afa40b49a9fec29a7f6e3edf5f7996d8’
NOTE: On one of the sites this file was compressed so I had to pipe it to gunzip –
$ curl … | gunzip z.html
File downloaded –
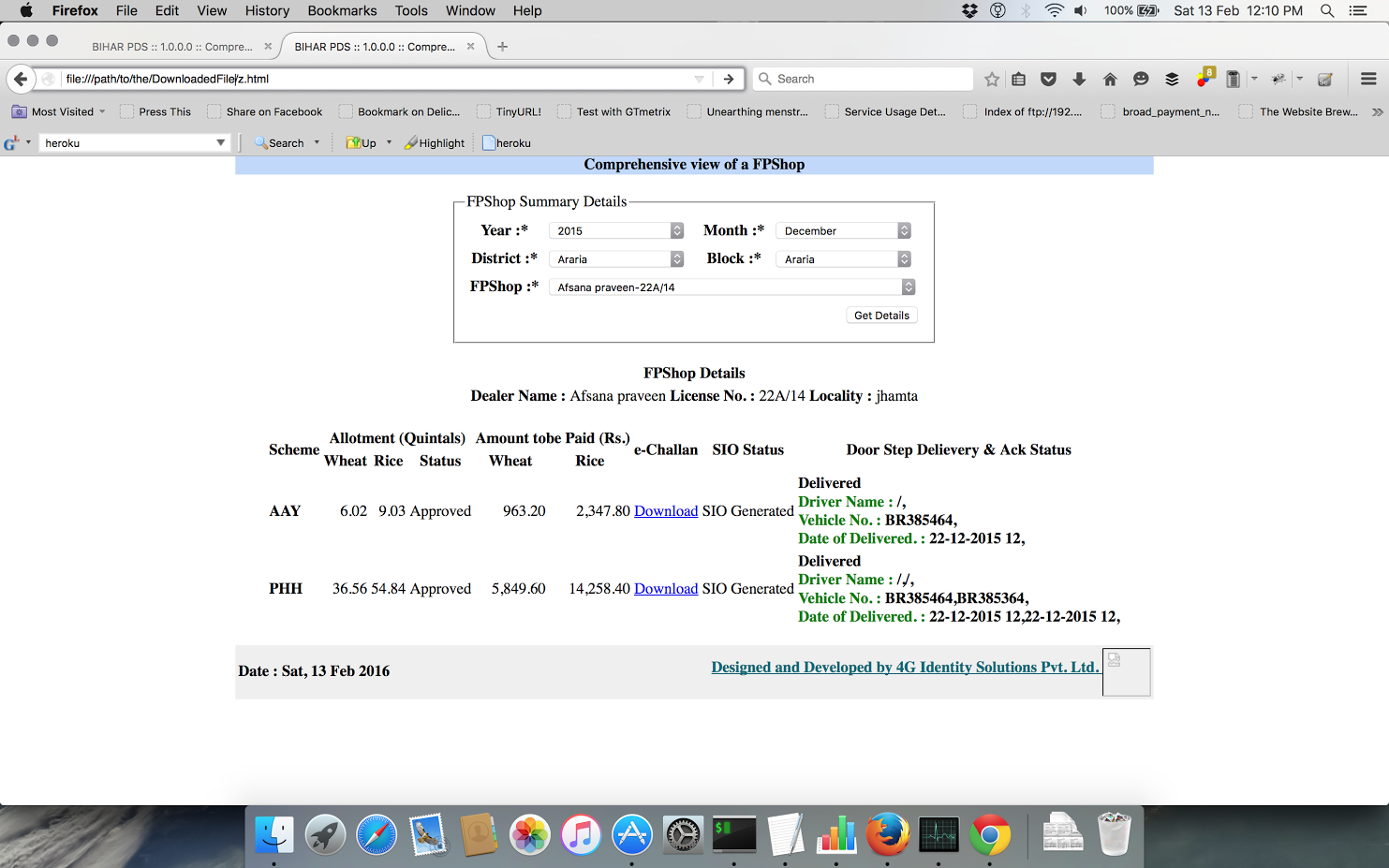
Now you can easily manipulate the date and district values to get the files of your interest.
In python programming, you could use Mechanize or the more basic httplib2. There is some debate here on requests vs urllib2 vs httplib2 –
https://gist.github.com/kennethreitz/973705
but I think a strong case built here for httplib2 –
http://www.diveintopython3.net/http-web-services.html
You could stick to whatever works for you. I chose httplib2 with Python 3.5 influenced by DiveIntoPython.
Here is what the script looked like finally –
If you wish to try the same in Python, you can via this snippet –
#! /usr/bin/env python
from urllib.parse import urlencode
import httplib2
httplib2.debuglevel = 1
h = httplib2.Http(‘.cache’)
data = {
‘mode’:’searchFPShopDetails’,
‘dyna(state_id)’:’10’,
‘dyna(fpsCode)’:”,
‘dyna(scheme_code)’:”,
‘dyna(year)’:’2015′,
‘dyna(month)’:’12’,
‘dyna(district_id)’:’1001′,
‘dyna(block_id)’:’10010125′,
‘dyna(fpshop_id)’:’200000016602′,
}
print(urlencode(data))
response, content = h.request(url, ‘POST’, urlencode(data), headers = {‘Content-Type’: ‘application/x-www-form-urlencoded’})
with open(‘z.html’, ‘wb’) as html_file:
print(‘Writing z.html’)
html_file.write(content)